В компьютерном зрении перекрёстный оператор Робертса — один из ранних алгоритмов выделения границ, который вычисляет сумму квадратов разниц между диагонально смежными пикселами. Это может быть выполнено сверткой изображения с двумя ядрами:
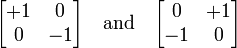
Иными словами, каждый пиксель получаемого изображения вычисляется по правилу:
a = input_image(x, y) - input_image(x + 1, y + 1)
b = input_image(x + 1,y) - input_image(x, y + 1)
output_image(x, y) = sqrt(a^2 + b^2)
Что это всё значит разберём чуть позже, а пока давайте взглянем на работу фильтра:






Описание программы
Изображение является двоичным файлом со следующей структурой:
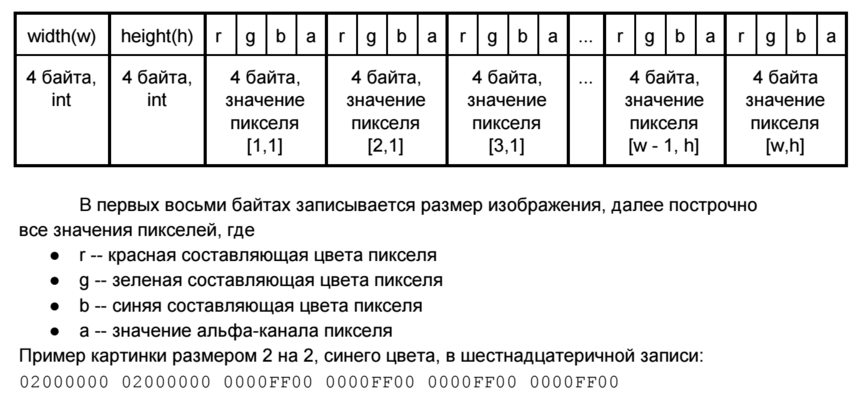
Входное и выходное изображения храняться в массивах:
int *input = new int[w * h];
int *output = new int[w * h];
Так как четыре компоненты цвета храняться в одном int, то для работы с ними на GPU используется распаковка и запаковка их обратно с помощью сдвигов (подсмотрено в примерах CUDA):
__device__ int pack(int4 rgba)
{
return (rgba.w << 24) | (rgba.z << 16) | (rgba.y << 8) | rgba.x;
}
__device__ int4 unpack(int c)
{
int4 rgba;
rgba.x = c & 0xff;
rgba.y = (c>>8) & 0xff;
rgba.z = (c>>16) & 0xff;
rgba.w = (c>>24) & 0xff;
return rgba;
}
Яркость находится из формул конверсии RGB -> YUV:
Y = 0.299 * R + 0.587 * G + 0.114 * B;
U = -0.14713 * R - 0.28886 * G + 0.436 * B + 128;
V = 0.615 * R - 0.51499 * G - 0.10001 * B + 128;
здесь Y — яркостная составляющая, U и V — цветоразностные составляющие.
В итоге для яркости:
__device__ double intensity(int4 rgba)
{
return 0.299 * rgba.x + 0.587 * rgba.y + 0.114 * rgba.z;
}
Для каждого пикселя нового изображения (матрицы w* h) считается новое значение цвета по формуле для перекрёстного оператора Робертса:
double m = intensity(unpack(get_element(dev_input, w, h, i, j)));
double br = intensity(unpack(get_element(dev_input, w, h, i + 1, j + 1)));
double r = intensity(unpack(get_element(dev_input, w, h, i, j + 1)));
double b = intensity(unpack(get_element(dev_input, w, h, i + 1, j)));
double tmp1 = m - br;
double tmp2 = r - b;
int gradient = (int) sqrt(tmp1 * tmp1 + tmp2 * tmp2);
// Нормировка
if(gradient > 255) gradient = 255;
// Записываем интенсивность в RGB
dev_output[i * w + j] = pack(make_int4(gradient, gradient, gradient, 0));
Работа программы была проверена на различных вычислительных сетках (количество блоков и потоков).
Для построения графиков использовался Python + matplotlib.
import os
from os.path import basename, splitext
from numpy import linspace, array
import matplotlib
import matplotlib.pyplot as plt
from scipy.interpolate import interp1d
from multiprocessing import Pool
# Настройка шрифтов
matplotlib.rc('font', family='Tahoma', size=16)
matplotlib.rc('axes', titlesize=22)
matplotlib.rc('axes', labelsize=18)
matplotlib.rc('legend', fontsize=16)
matplotlib.rc('xtick', labelsize=12)
matplotlib.rc('ytick', labelsize=12)
# Время выполнения для теста <size> для программы <program_name>
def calculate_time(params):
program_name = params['program_name']
size = params['size']
in_name = 'in{}.data'.format(size)
if not os.path.isfile(in_name):
return None
out_name = 'out{}.data'.format(size)
output = os.popen('echo {} {} | {}'.format(in_name, out_name, program_name)).read()
output = float(output)
print('Программа {}, тест {}, время {} мс'.format(program_name, in_name, output))
return {'size': size, 'time': output}
# Расчёт времени выполнения для сеток от 1x1 до 3000x3000 для существующих тестов
def run_test_for_program(program_name):
params = [{'program_name': program_name, 'size': n} for n in range(3000 + 1)]
result = Pool(4).map(calculate_time, params)
result = [x for x in result if x is not None]
x = array([float(x['size']) for x in result])
y = array([x['time'] for x in result])
return x, y
# Данные измерений
def get_functions():
return [
{
'label': 'блоки: 8x8, потоки: 16x16',
'color': 'red',
'data': run_test_for_program('lab2_8x8_16x16.exe')
},
{
'label': 'блоки: 16x16, потоки: 16x16',
'color': 'green',
'data': run_test_for_program('lab2_16x16_16x16.exe')
},
{
'label': 'блоки: 32x32, потоки: 16x16',
'color': 'blue',
'data': run_test_for_program('lab2_32x32_16x16.exe')
},
{
'label': 'блоки: 8x8, потоки: 32x32',
'color': 'purple',
'data': run_test_for_program('lab2_8x8_32x32.exe')
},
{
'label': 'блоки: 16x16, потоки: 32x32',
'color': 'orange',
'data': run_test_for_program('lab2_16x16_32x32.exe')
},
{
'label': 'блоки: 32x32, потоки: 32x32',
'color': 'pink',
'data': run_test_for_program('lab2_32x32_32x32.exe')
}
]
# Функция апроксимации
def fit_quadratic_function(x, a, b, c):
return a * x ** 2 + b * x + c
def main():
plt.figure(figsize=(22, 11), dpi=80)
x_min, x_max = None, None
y_min, y_max = None, None
for f in get_functions():
label = f['label']
color = f['color']
x, y = f['data']
if not all([x_min, x_max, y_min, y_max]):
x_min, x_max = x.min(), x.max()
y_min, y_max = y.min(), y.max()
else:
x_min, x_max = min(x_min, x.min()), max(x_max, x.max())
y_min, y_max = min(y_min, y.min()), max(y_max, y.max())
x_new = linspace(x.min(), x.max(), 100)
f = interp1d(x, y, kind='cubic')
plt.plot(x, y, marker='o', linestyle='', color=color)
plt.plot(x_new, f(x_new), linestyle='-', color=color, label=label)
# Внешний вид
plt.xlim([x_min, x_max])
plt.ylim([y_min, y_max])
plt.xlabel('Размер матрицы')
plt.ylabel('Время выполнения, мс')
plt.legend(loc='best')
plt.grid(True)
# Сохранить в PNG и показать
file_name, file_extension = splitext(__file__)
plt.savefig('{:s}.png'.format(basename(file_name)))
plt.show()
if __name__ == "__main__":
main()
Графики производительности для разных сеток:
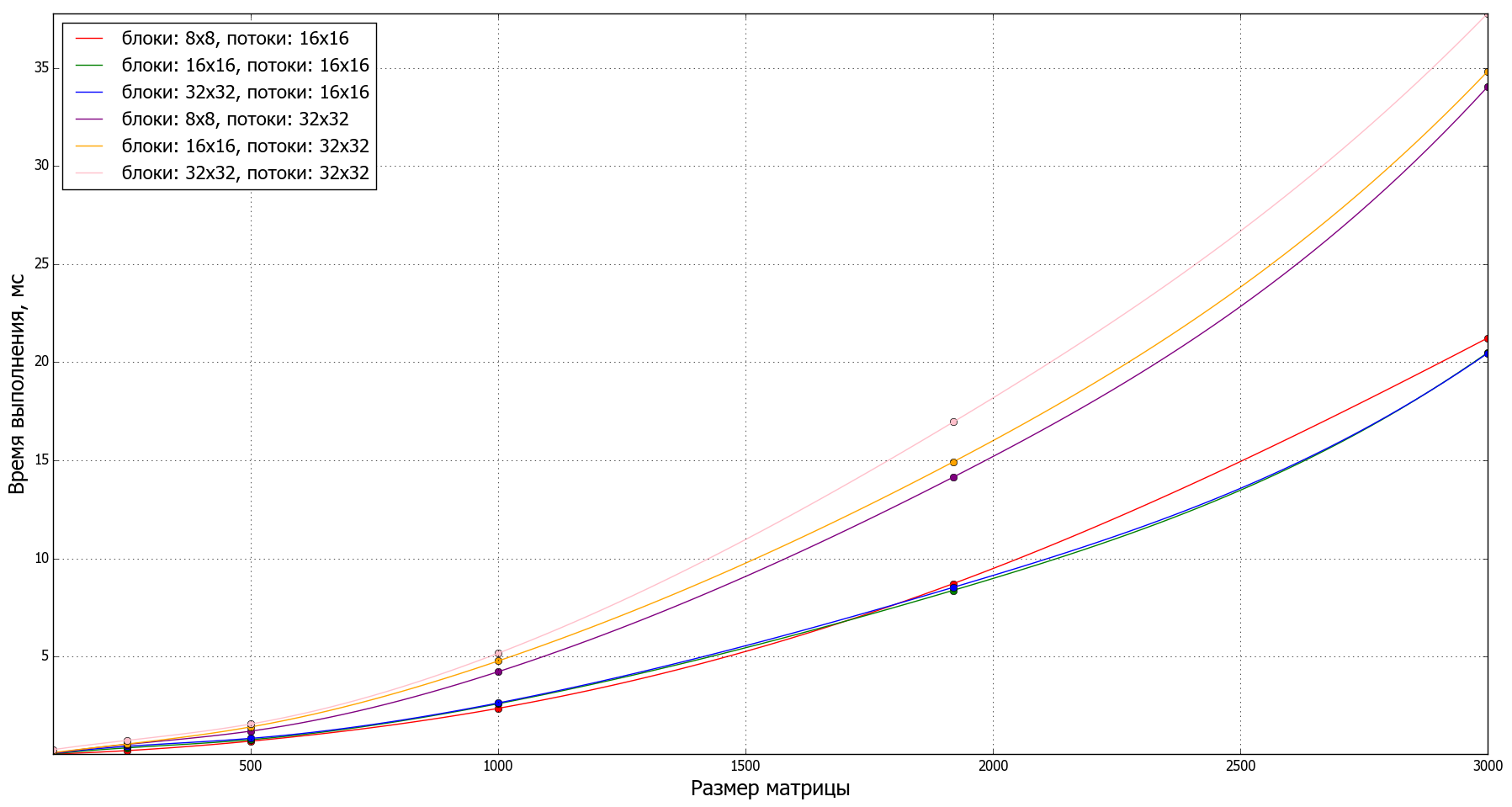
Полный код программы (CUDA C++):
#include <iostream>
#include <fstream>
#include <iomanip>
#include <string>
#include <cmath>
#include <algorithm>
#define uint unsigned int
#define DEBUG true
#define DEBUG_MATRIX false
#define DEBUG_TIMER true
using namespace std;
void print(int *matrix, int w, int h) {
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
int c = matrix[i * w + j];
cout << setw(4) << (int)(c & 0xff) << ",";
cout << setw(4) << (int)((c >> 8) & 0xff) << ",";
cout << setw(4) << (int)((c >> 16) & 0xff) << ",";
cout << setw(4) << (int)((c >> 24) & 0xff) << "\t";
}
cout << endl;
}
}
__device__ int get_element(int *input, int w, int h, int i, int j) {
i = max(0, min(i, h - 1));
j = max(0, min(j, w - 1));
return input[i * w + j];
}
__device__ int pack(int4 rgba) {
return (rgba.w << 24) | (rgba.z << 16) | (rgba.y << 8) | rgba.x;
}
__device__ int4 unpack(int c) {
int4 rgba;
rgba.x = c & 0xff;
rgba.y = (c >> 8) & 0xff;
rgba.z = (c >> 16) & 0xff;
rgba.w = (c >> 24) & 0xff;
return rgba;
}
__device__ double intensity(int4 rgba) {
return 0.299 * rgba.x + 0.587 * rgba.y + 0.114 * rgba.z;
}
__global__ void roberts_cross_kernel(int *input, int *output, int w, int h) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
int idy = blockIdx.y * blockDim.y + threadIdx.y;
int offsetx = gridDim.x * blockDim.x;
int offsety = gridDim.y * blockDim.y;
for (int i = idx; i < h; i += offsetx) {
for (int j = idy; j < w; j += offsety) {
double m = intensity(unpack(get_element(input, w, h, i, j)));
double br = intensity(unpack(get_element(input, w, h, i + 1, j + 1)));
double r = intensity(unpack(get_element(input, w, h, i, j + 1)));
double b = intensity(unpack(get_element(input, w, h, i + 1, j)));
double tmp1 = m - br;
double tmp2 = r - b;
// Нормировка
int result = min(255, (int)sqrt(tmp1 * tmp1 + tmp2 * tmp2));
// Записываем интенсивность в RGB
output[i * w + j] = pack(make_int4(result, result, result, 0));
}
}
}
void roberts_cross_gpu(int *input, int *output, int w, int h) {
dim3 BLOCKS(16, 16);
dim3 THREADS(32, 32);
int *dev_input;
int *dev_output;
cudaMalloc(&dev_input, sizeof(int) * w * h);
cudaMalloc(&dev_output, sizeof(int) * w * h);
cudaMemcpy(dev_input, input, sizeof(int) * w * h, cudaMemcpyHostToDevice);
cudaMemcpy(dev_output, output, sizeof(int) * w * h, cudaMemcpyHostToDevice);
cudaEvent_t start, stop;
if (DEBUG && DEBUG_TIMER) {
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
}
roberts_cross_kernel<<<BLOCKS, THREADS>>>(dev_input, dev_output, w, h);
if (DEBUG && DEBUG_TIMER) {
cudaGetLastError();
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float t;
cudaEventElapsedTime(&t, start, stop);
cout << t << endl;
cudaEventDestroy(start);
cudaEventDestroy(stop);
}
cudaMemcpy(output, dev_output, sizeof(int) * w * h, cudaMemcpyDeviceToHost);
cudaFree(dev_input);
cudaFree(dev_output);
}
int main() {
string path_in;
cin >> path_in;
string path_out;
cin >> path_out;
int w, h;
ifstream input_stream;
input_stream.open(path_in.c_str(), ios::binary);
// Размеры изображения
input_stream.read((char *)&w, sizeof(int));
input_stream.read((char *)&h, sizeof(int));
// Входное и выходное изображения
int *input = new int[w * h];
int *output = new int[w * h];
input_stream.read((char *)input, sizeof(int) * w * h);
input_stream.close();
if (DEBUG && DEBUG_MATRIX) {
cout << "Before:" << endl;
print(input, w, h);
cout << endl;
}
roberts_cross_gpu(input, output, w, h);
if (DEBUG && DEBUG_MATRIX) {
cout << "After:" << endl;
print(output, w, h);
cout << endl;
}
// Запись в файл
ofstream output_stream;
output_stream.open(path_out.c_str(), ios::binary);
output_stream.write((char *)&w, sizeof(int));
output_stream.write((char *)&h, sizeof(int));
output_stream.write((char *)output, sizeof(int) * w * h);
output_stream.close();
delete[] input;
delete[] output;
return 0;
}